728x90
반응형
SMALL
scikit-learn 특징
- 다양한 머신러닝 알고리즘을 구현한 파이썬 라이브러리
- 심플하고 일관성 있는 API, 유용한 온라인 문서, 풍부한 예제
- 머신러닝을 위한 쉽고 효율적인 개발 라이브러리 제공
- 다양한 머신러닝 관련 알고리즘과 개발을 위한 프레임워크와 API 제공
- 많은 사람들이 사용하며 다양한 환경에서 검증된 라이브러리
scikit-learn 주요 모듈
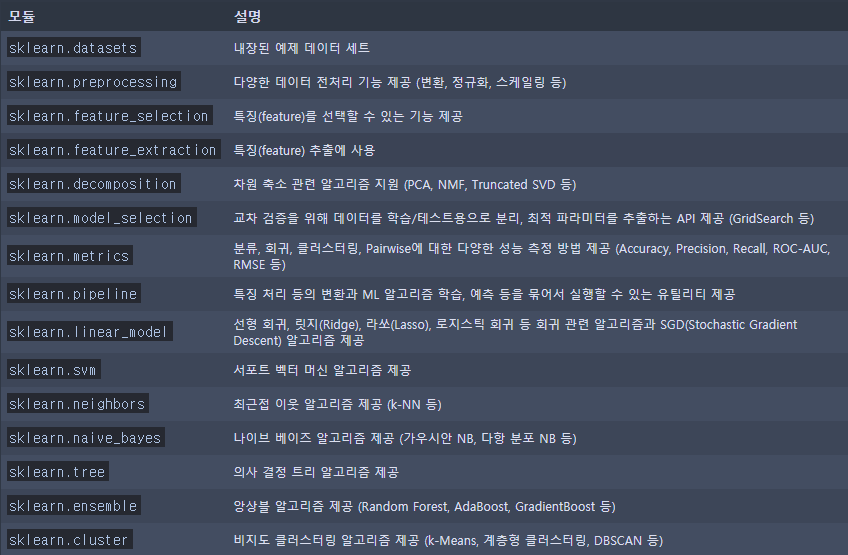
estimator API
- 일관성: 모든 객체는 일관된 문서를 갖춘 제한된 메서드 집합에서 비롯된 공통 인터페이스 공유
- 검사(inspection): 모든 지정된 파라미터 값은 공개 속성으로 노출
- 구성: 많은 머신러닝 작업은 기본 알고리즘의 시퀀스로 나타낼 수 있으며, Scikit-Learn은 가능한 곳이라면 어디서든 이 방식을 사용
- 합리적인 기본값: 모델이 사용자 지정 파라미터를 필요로 할 때 라이브러리가 적절한 기본값을 정의
API 사용 방법
- Scikit-Learn으로부터 적절한 estimator 클래스를 임포트해서 모델의 클래스 선택
- 클래스를 원하는 값으로 인스턴스화해서 모델의 하이퍼파라미터 선택
- 데이터를 특징 배열과 대상 벡터로 배치
- 모델 인스턴스의 fit() 메서드를 호출해 모델을 데이터에 적합
예제 데이터 세트
- 분류 또는 회귀용 데이터 세트
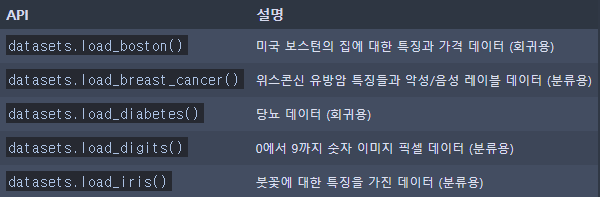
- 온라인 데이터 세트 (데이터 크기가 커서 온라인에서 데이터를 다운로드 한 후에 불러오는 예제 데이터 세트)

- 분류와 클러스터링을 위한 표본 데이터 생성

예제 데이터 세트 구조
- 일반적으로 딕셔너리 형태로 구성
- data: 특징 데이터 세트
- target: 분류용은 레이블 값, 회귀용은 숫자 결과값 데이터
- target_names: 개별 레이블의 이름 (분류용)
- feature_names: 특징 이름
- DESCR: 데이터 세트에 대한 설명과 각 특징 설명
sklearn 라이브러리기본구조
import numpy as np # numpy 패키지 가져오기 import matplotlib.pyplot as plt # 시각화 패키지 가져오기 ## 2.데이터 가져오기 import pandas as pd # csv -> dataframe으로 전환 from sklearn import datasets # python 저장 데이터 가져오기 ## 3.데이터 전처리 from sklearn.preprocessing import StandardScaler # 연속변수의 표준화 from sklearn.preprocessing import LabelEncoder # 범주형 변수 수치화 # 4. 훈련/검증용 데이터 분리 from sklearn.model_selection import train_test_split ## 5.분류모델구축 from sklearn.tree import DecisionTreeClassifier # 결정 트리 from sklearn.naive_bayes import GaussianNB # 나이브 베이즈 from sklearn.neighbors import KNeighborsClassifier # K-최근접 이웃 from sklearn.ensemble import RandomForestClassifier # 랜덤 포레스트 from sklearn.ensemble import BaggingClassifier # 앙상블 from sklearn.linear_model import Perceptron # 퍼셉트론 from sklearn.linear_model import LogisticRegression # 로지스틱 회귀 모델 from sklearn.svm import SVC # 서포트 벡터 머신(SVM) from sklearn.neural_network import MLPClassifier # 다층인공신경망 ## 6.모델검정 from sklearn.metrics import confusion_matrix, classification_report # 정오분류표 from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score # 정확도, 민감도 등 from sklearn.metrics import roc_curve, auc # ROC 곡선 그리기 ## 7.최적화 from sklearn.model_selection import cross_validate # 교차타당도 from sklearn.pipeline import make_pipeline # 파이프라인 구축 from sklearn.model_selection import learning_curve, validation_curve # 학습곡선, 검증곡선 from sklearn.model_selection import GridSearchCV # 하이퍼파라미터 튜닝
review
- sklearn 기본 구조
728x90
반응형
LIST
'코딩으로 익히는 Python > 모델링' 카테고리의 다른 글
| [Python] 5. 문자열encoding : LabelEncoder, OneHotEncoder, get_dummies(), make_column_transformer 예제 (0) | 2021.01.20 |
|---|---|
| [Python] 4. 다중선형회귀 : 릿지L2규제, 라쏘L1규제, 엘라스틱넷 (0) | 2021.01.20 |
| [Python] 3. 다중선형회귀 (0) | 2021.01.20 |
| [Python] 2. 정규화 : 상관관계, 다중공선성 (0) | 2021.01.20 |
| [Python] 1. 선형회귀분석 (0) | 2021.01.20 |



