728x90
반응형
SMALL
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.model_selection import cross_val_score, cross_validate
import multiprocessing
import os
from sklearn.datasets import load_iris
from sklearn.pipeline import make_pipeline, Pipeline
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, export_graphviz,export_text, plot_tree
from sklearn import metrics
import graphviz
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
Decision Tree(의사결정나무)
- 분류와 회귀에 사용되는 지도 학습 방법
- 데이터 특성으로 부터 추론된 결정 규칙을 통해 값을 예측
- if-then-else 결정 규칙을 통해 데이터 학습
- 트리의 깊이가 깊을 수록 복잡한 모델
- 결정 트리 장점 : 이해와 해석이 쉽다, 시각화가 용이하다, 많은 데이터 전처리가 필요하지 않다, 수치형과 범주형 데이터 모두를 다룰 수 있다
엔트로피
지니계수를 이용하여 데이터 분할
- 지니계수 : 경제학에서 불평등지수를 나타낼 때 사용하는
- 것으로 0일 때 완전 평등, 1일 때 완전 불평등을 의미
- 머신러닝에서는 데이터가 다양한 값을 가질수록 평등하며 특정 값으로 쏠릴 때 불평등한 값이 됩니다.
- 다양성이 낮을수록 균일도가 높다는 의미로 1로 갈수록 균일도가 높아 지니계수가 높은 속성을 기준으로 분할
Decision Tree Classifier의 핵심 파라미터
- min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터수 ( 과적합을 제어하는데 사용 ), Default = 2 → 작게 설정할 수록 분할 노드가 많아져 과적합 가능성 증가
- min_samples_leaf: 리프노드가 되기 위해 필요한 최소한의 샘플 데이터수, min_samples_split과 함께 과적합 제어 용도,불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요
- max_features: 최적의 분할을 위해 고려할 최대 feature 개수, Default = None → 데이터 세트의 모든 피처를 사용, int형으로 지정 →피처 갯수 / float형으로 지정 →비중, sqrt 또는 auto : 전체 피처 중 √(피처개수) 만큼 선정, log : 전체 피처 중 log2(전체 피처 개수) 만큼 선정
- max_depth : 트리의 최대 깊이, default = None → 완벽하게 클래스 값이 결정될 때 까지 분할 또는 데이터 개수가 min_samples_split보다 작아질 때까지 분할, 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요
- max_leaf_nodes: 리프노드의 최대 개수
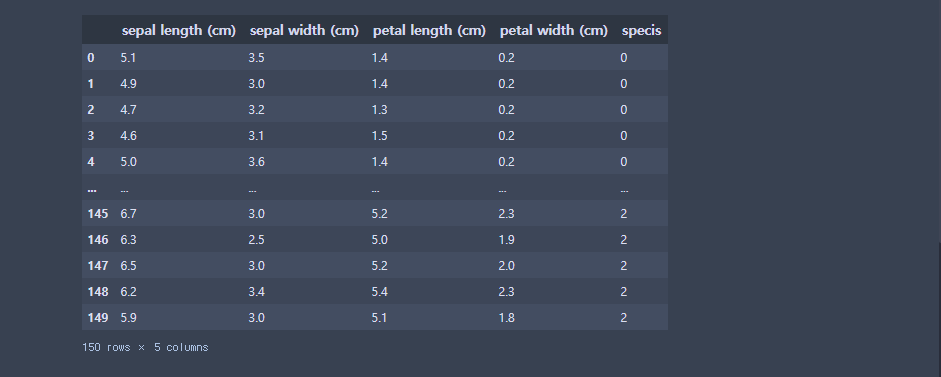
iris = load_iris()iris_df = pd.DataFrame( iris.data)
iris_df.columns = iris['feature_names']
iris_df['specis'] = iris.target
iris_df
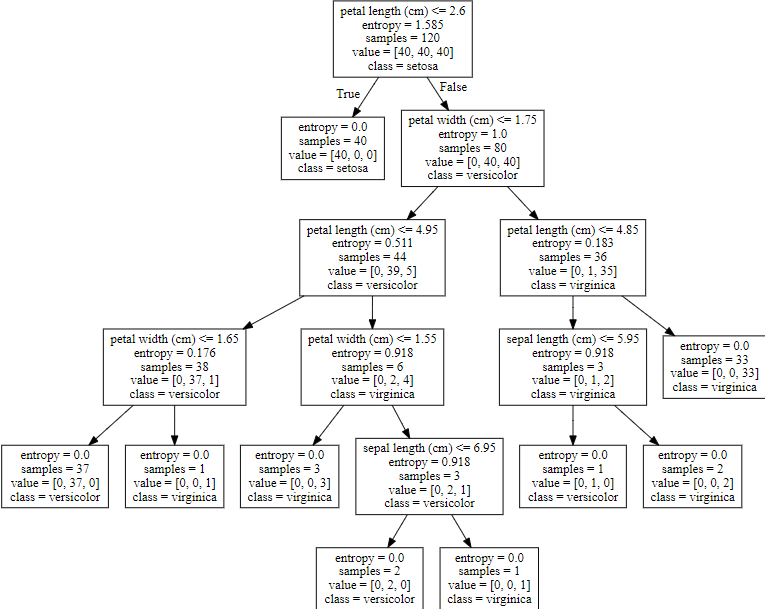
model_tree = DecisionTreeClassifier(criterion="entropy")
x_train, x_test, y_train, y_test = train_test_split(iris['data'],iris['target'],test_size=0.2,
random_state=11,stratify=iris['target'])
model_tree.fit(x_train,y_train)[OUT] :
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='entropy',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
export_graphviz(model_tree, out_file='tree.dot', class_names=iris['target_names'],
feature_names=iris['feature_names'])
- export_graphviz 설치 폴더를 인식시켜주어야 함 (아래 첨부된 링크에서 다운로드)
- (중요)아래와 같이 \ 로 표시되면 에러가 발생함
- os.environ['PATH'] += os.pathsep + 'C:\Program Files (x86)\Graphviz2.38\bin'
- \ --> /
https://www2.graphviz.org/Packages/stable/windows/10/msbuild/Release/Win32/
Index of /Packages/stable/windows/10/msbuild/Release/Win32
www2.graphviz.org
# os.environ['PATH'] += os.pathsep + 'C:/Users/master14/graphviz-2.44.1-win32/Graphviz/bin'
os.environ['PATH'] += os.pathsep + r'C:\Users\master14\graphviz-2.44.1-win32\Graphviz\bin'
# \에러나면 앞에 r붙여주면 됨
with open('tree.dot') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
# 이미지 사이즈 조정
# !pip install pydotplus
# import pydotplus
# pydot_graph = pydotplus.graph_from_dot_data(dot_graph)
# pydot_graph.set_size('"10,9!"')
# pydot_graph.write_png('resized_tree.png')
# gvz_graph = graphviz.Source(pydot_graph.to_string())
# gvz_graph
model_tree.score(x_train,y_train) # 과적합 의심[OUT] :
1.0
model_tree.score(x_test,y_test)[OUT] :
1.0
model_tree.feature_importances_ # 불순도 높은~낮은 : 불순도가 낮을수록 분류가 명확함[OUT] :
array([0.0144845 , 0.0144845 , 0.07429684, 0.89673415])
sns.barplot(x=model_tree.feature_importances_,y=iris['feature_names'])
plt.show()
# petal width가 가장 잘 분류하는 것으로 나타남

과소 or 과대 적합 확인
from sklearn.model_selection import validation_curve
pipe_tree = make_pipeline(DecisionTreeClassifier(criterion="entropy"))
# pipleline필수 스케일링 필요하면 해야함
param_range = [2,3,4,5,6,7,8,9,10]
train_score, test_score = validation_curve(estimator=pipe_tree,X=x_train,y=y_train,
param_name = "decisiontreeclassifier__max_depth",
param_range = param_range, scoring='f1_macro', cv=5, verbose=1)
# scoring='f1_macro' multi라서 _macro 안붙여주면 error[OUT] :
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 45 out of 45 | elapsed: 0.0s finished
train_score.mean(axis=1)[OUT] :
array([0.95403079, 0.96452569, 0.98122707, 0.98957468, 0.99583232,
1. , 1. , 1. , 1. ])
test_score.mean(axis=1)[OUT] :
array([0.91532779, 0.91532779, 0.92457205, 0.92457205, 0.92457205,
0.92457205, 0.92457205, 0.91633676, 0.91633676])
plt.ylim(0.8,1.2)
plt.plot(param_range, train_score.mean(axis=1),'r--')
plt.plot(param_range, test_score.mean(axis=1),'b--')
plt.show()
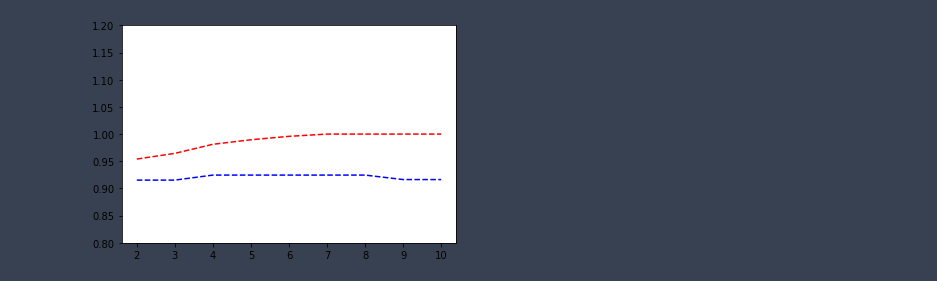
결론
- depth가 4인경우 가장 차이가 적음
연습문제
breast_cancer데이터셋 decisiontree, validation curve를 그리시오
Solution
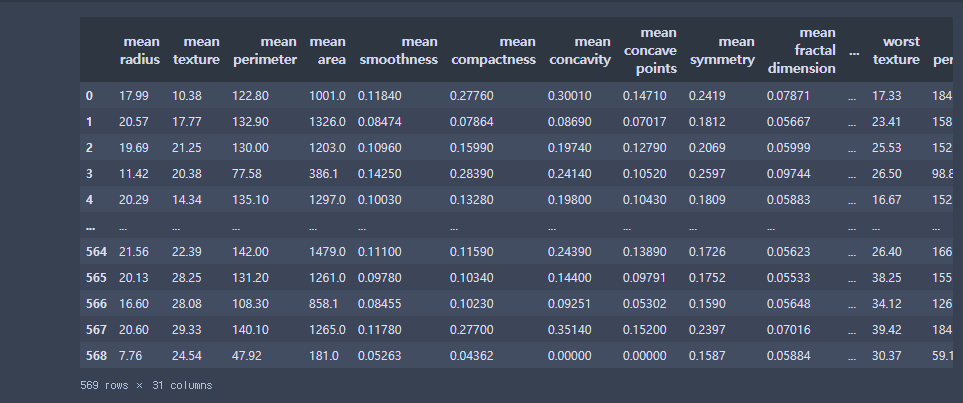
cancer = load_breast_cancer()
cancer_df = pd.DataFrame(cancer.data)
cancer_df.columns = cancer['feature_names']
cancer_df['diagnosis'] = cancer.target
cancer_df
model_cancer = DecisionTreeClassifier(criterion="entropy")
x_train, x_test, y_train, y_test = train_test_split(cancer['data'],
cancer['target'], test_size=0.2,random_state=11,stratify=cancer['target'] )
model_cancer.fit(x_train,y_train)[OUT] :
DecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='entropy',
max_depth=None, max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort='deprecated',
random_state=None, splitter='best')
export_graphviz(model_cancer, out_file='cancer.dot', class_names=cancer['target_names'],
feature_names=cancer['feature_names'])
with open('cancer.dot') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)

pipe_cancer = make_pipeline(DecisionTreeClassifier(criterion="entropy"))
param_range = [2,3,4,5,6,7,8,9,10]
train_score, test_score = validation_curve(estimator=pipe_cancer,X=x_train,y=y_train,
param_name = "decisiontreeclassifier__max_depth",
param_range = param_range, scoring='f1_macro', cv=5, verbose=1)[OUT] :
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 45 out of 45 | elapsed: 0.1s finished
print(f'train_score_mean :{train_score.mean(axis=1)}')
print(f'test_score_mean : {test_score.mean(axis=1)}')
plt.ylim(0.8,1.2)
plt.plot(param_range, train_score.mean(axis=1),'r--')
plt.plot(param_range, test_score.mean(axis=1),'b--')
plt.show()

결론
- 결정트리는 과적합이 많이 일어나기 때문에 교차검증 필수
728x90
반응형
LIST
'코딩으로 익히는 Python > 모델링' 카테고리의 다른 글
| [Python] 19. MLP : pima-indians 예제 (0) | 2021.01.26 |
|---|---|
| [Python] 18. Ensemble(앙상블) : breast_cancer,wine 예제 (5) | 2021.01.25 |
| [Python] 16. 강아지&고양이 이미지 분류 실습 (0) | 2021.01.24 |
| [Python] 15. 이미지분류 : mnist, MLPClassifier (0) | 2021.01.24 |
| [Python] 14. NN : XOR문제, MLPClassifier (0) | 2021.01.22 |



