728x90
반응형
SMALL
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from datetime import datetime
from pandas_datareader import data
matplotlib.rcParams['font.family']='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] = False
데이터 불러오기 (pd.read_csv)
python 파일 경로에 data폴더 만든 후 다음의 파일들 넣어놓기
2014년 졸음운전 교통사고.csv
0.00MB
2015년 졸음운전 교통사고.csv
0.00MB
2016년 졸음운전 교통사고.csv
0.00MB
data1 = pd.read_csv('data/2014년 졸음운전 교통사고.csv',encoding='euc-kr')
data2 = pd.read_csv('data/2015년 졸음운전 교통사고.csv',encoding='euc-kr')
data3 = pd.read_csv('data/2016년 졸음운전 교통사고.csv',encoding='euc-kr') 연습문제
1. 3개의 데이터를 병합하시오
====이후문제는 병합한 데이터프레임을 이용 ===========
2. 년도, 월별로 인덱스를 설정(멀티인덱스) 하고 데이터를 보여 주시오
3. 년도 및 월별 평균 사망자를 보여주시오
4. 2016년 사고대비 사망율을 구하시오
5. 2014년도 월별 사망, 부상 데이터를 바차트로 보여주시오
6. 2015년 대비 사망이 가장 많이 증가한 2016년도 월을 구하시오
Solution
1. 3개의 데이터를 병합하시오
data = pd.concat([data1,data2,data3])
data.set_index('구분',inplace=True)
data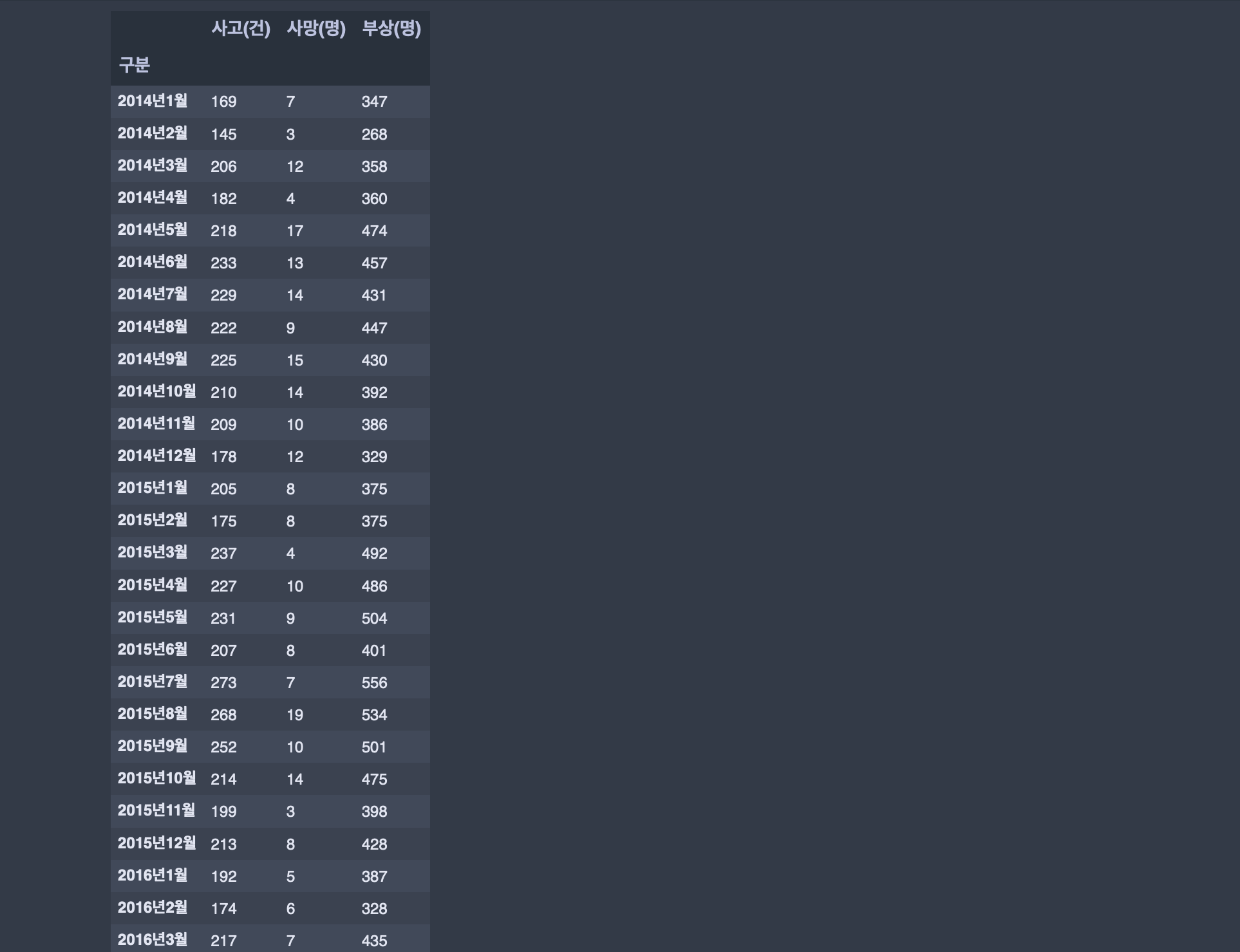
...
2. 년도, 월별로 인덱스를 설정(멀티인덱스) 하고 데이터를 보여 주시오
ans2 = data.copy()
ans2.index = pd.to_datetime(ans2.index, format='%Y년%m월')
ans2.set_index([ans2.index.year,ans2.index.month], inplace=True)
ans2.index.names = ['년도','월']
ans2
...
3. 년도 및 월별 평균 사망자를 보여주시오
y = ans2.groupby('년도').mean()[['사망(명)']]
m = ans2.groupby('월').mean()[['사망(명)']]
y, m[OUT] :
( 사망(명)
년도
2014 10.833333
2015 9.000000
2016 8.166667,
사망(명)
월
1 6.666667
2 5.666667
3 7.666667
4 7.000000
5 13.000000
6 11.000000
7 10.000000
8 11.666667
9 12.666667
10 12.666667
11 6.000000
12 8.000000)
4. 2016년 사고대비 사망율을 구하시오
d_2016 = ( ans2.loc[2016])['사망(명)'].sum()/( ans2.loc[2016])['사고(건)'].sum()
d_2016[OUT] :
0.04027949034114262
5. 2014년도 월별 사망, 부상 데이터를 바차트로 보여주시오
ans2.loc[2014][['사망(명)','부상(명)']].plot(kind='bar',rot=0)
plt.show()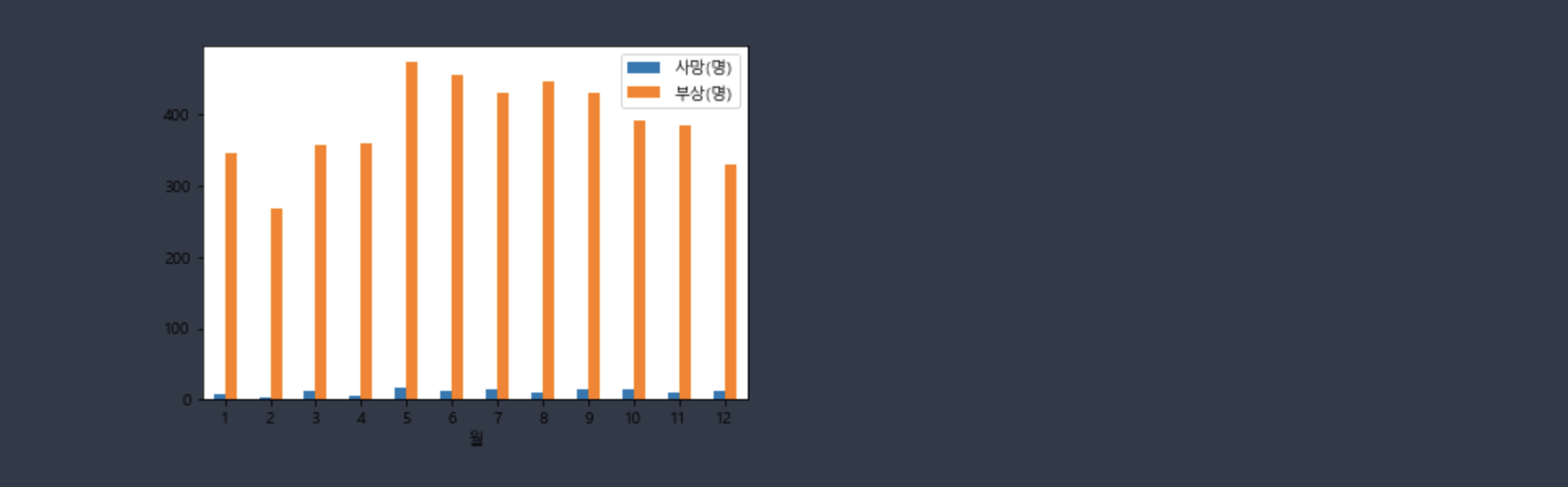
6. 2015년 대비 사망이 가장 많이 증가한 2016년도 월을 구하시오
(ans2.loc[2016,'사망(명)'] - ans2.loc[2015,'사망(명)']).nlargest(1,keep='all')[OUT] :
월
5 4
6 4
Name: 사망(명), dtype: int64review
- 문제만보고 직접 풀어보기
728x90
반응형
LIST



